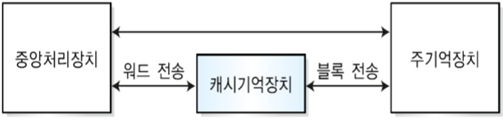
1. 캐시 기억장치
- 주기억장치에 저장되어 있는 명령어와 데이터 중의 일부를 임시적으로 복사해 저장하는 장치
1) 특징
- 명령어와 데이터를 저장하고 인출하는 속도가 주기억장치보다 빠름
- 자주 사용되는 명령들을 저장해 두었다 중앙처리장치(CPU)에 빠른 속도로 제공함
- 동작이 느린 주기억장치와 빠른 CPU 사이에서 속도차이를 줄여주는 고속 완충기억장치의 역할을 한다
- 캐시기억장치의 용량에 의해 CPU의 가격이 결정된다

* 확인해서 캐시 기억장치에 CPU가 원하는 데이터가 있다면 캐시 기억장치에서 가져옴
2) 캐시 기억장치가 없는 시스템의 동작 원리
- CPU가 명령어와 데이터를 인출하기 위해선 주기억장치에 접근해야 된다
- 주기억장치에서 명령어 혹은 필요한 정보를 획득해 CPU내의 명령어 레지스터에 저장한다
* 주기억장치는 CPU에 비해 느려 성능이 낮음

3) 캐시 기억장치가 있는 시스템
(1) 동작 원리
- CPU가 명령어 혹은 데이터를 인출할 때 캐시기억장치를 가장 먼저 조사한다
- hit : CPU가 명령어를 인출하기 위해 캐시기억장치에 접근해 원한 명령어를 찾은 상황
- miss : CPU가 명령어를 인출하기 위해 캐시기억장치에 접근했지만 원하는 명령어가 존재하지 않아 찾지 못함
(2) miss
- CPU에 명령어를 인출하기 위해 캐시기억장치에 접근했을 때 원한 명령어가 없는 경우

- 만약 1000번지 워드를 읽어야 한다면 처음엔 캐시 기억장치에 있는지 확인한다.
하지만 없으므로 miss상태가 되어 다음과 같이 처리한다
* 워드 : CPU가 한 번에 처리할 수 있는 크기
블록 : 워드가 2개 이상 쌓인 상태

- 주기억장치에서 필요한 정보를 캐시기억장치로 전송한다 (보통 필요한 워드 외에도 나중에 사용할 것으로 예상되는 워드들도 같이 미리 전송함)
- 캐시기억장치에 정보들을 받으면 그중 필요한 정보를 CPU로 전송한다
(3) hit

- CPU에 명령어를 인출하기 위해 캐시기억장치에 접근했을 때 원한 명령어가 있는 경우
- 캐시 기억장치를 검사했을 때 CPU에서 필요한 정보를 갖고 있다면 hit상태로 보아 캐시 기억장치에서 얻은 정보를 CPU로 전송함
4) 캐시 기억장치 동작 원리

5) 캐시 기억장치의 적중률
- 적중률이 높을수록 데이터 액세스 속도가 향상됨
* 적중률 : 캐시 기억장치의 성능을 나타내는 척도
- 적중률 = ${적중수\over전체 메모리 참조 횟수}$
- $T_{average}$ = $H_{hit\_ratio}$ * $T_{cache}$ + (1 - $H_{hit\_ratio}$ ) * $T_{main}$
· $T_{average}$ : 주기억장치와 캐시 기억장치에서 데이터를 인출하는데 소요되는 평균 기억장치 접근 시간
· $T_{main}$ : 주기억장치 접근 시간
· $T_{cache}$ : 캐시 기억장치 접근 시간
· $H_{hit\_ratio}$ : 적중률
- 예시
▶ $T_{cache}$ = 50ns, $T_{main}$ = 400ns 일 때, 적중률을 증가시키며 기억장치 접근 시간을 계산
(1) 적중률이 70%인 경우 : $T_{average}$ = 0.7 * 50 + (1 – 0.7) * 400 = 155ns
(2) 적중률이 80%인 경우 : $T_{average}$ = 0.8 * 50 + (1 – 0.8) * 400 = 120ns
(3) 적중률이 90%인 경우 : $T_{average}$ = 0.9 * 50 + (1 – 0.9) * 400 = 85ns
(4) 적중률이 95%인 경우 : $T_{average}$ = 0.95 * 50 + (1 – 0.95) * 400 = 67.5ns
(5) 적중률이 99%인 경우 : $T_{average}$ = 0.99 * 50 + (1 – 0.99) * 400 = 53.5ns
2. 캐시 기억장치의 설계
- 주기억장치와 캐시 기억장치 간의 정보 공유
- 아래 나오는 것들을 모두 캐시 기억장치를 설계할 때 고려할 요소들이다
1) 캐시 기억장치의 크기
- 캐시 기억장치의 크기가 클수록, 적중률은 높아지거나 평균 접근 시간과 비용이 증가한다
- 적중률을 향상시키고 평균 접근 시간에 대한 저하를 막는 최적의 크기 결정이 필요한다
- 연구 결과에 의하면, 캐시 기억장치의 크기로 1K ~ 128K 단어가 최적이라고 알려져 있다
2) 인출방식
- 주기억장치에서 캐시 기억장치로 명령어나 데이터 블록을 인출해 오는 방식
(1) 요구인출 (Demand Fetch) 방식
- CPU가 현대 필요한 정보만을 주기억장치에서 블록 단위로 인출해 오는 방식
(2) 선인출 (Prefetch) 방식
- CPU가 현재 필요한 정보 외에도 앞으로 필요할 것 같다고 예측하는 정보를 미리 인출해 캐시 기억장치에 저장하는 방식 (컴퓨터에게 학습시켜야 된다)
- 주기억장치에서 명령어나 데이터를 인출할 때 필요한 정보와 이웃한 위치에 있는 정보들을 함께 인출해 캐시에 적재하는 방식
3) 사상함수

- 주기억장치의 구조
· 단어 : 하나의 주소 번지에 저장되는 데이터의 단위
· 블록 : K개의의 단어로 구성됨
- 캐시 기억장치의 구조
· 슬롯 : 데이터 블록이 저장되는 장소
· 태그 : 슬롯에 적재된 데이터 블록을 구분해주는 정보
· CPU는 캐시 기억장치에서 슬롯과 태그를 이용하여 필요한 정보를 찾는다
- 사상
: 주소를 연결시키는 작업으로 주기억장치와 캐시 기억장치 사이에서 정보를 옮기는 것

(1) 직접 사상
- 주소변환을 통해 주기억장치의 데이터 블록을 캐시기억장치에 저장하는 것
- 주소 형식

- 캐시 기억장치로부터 데이터 블록 인출을 위해 데이터 블록의 슬롯번호에 해당하는 슬롯만 검색하면 된다
- 장점 : 사상 과정이 간단
- 단점 : 동일한 슬롯 번호를 갖지만 태그가 다른 데이터 블록들에 대한 반복적인 접근을 적중률을 떨어뜨림 (태그가 같아도 같은 문제가 발생한다)
다음은 직접 사상의 예시다.
(1) CPU가 00001주소 번지 블록을 필요로 하는 경우
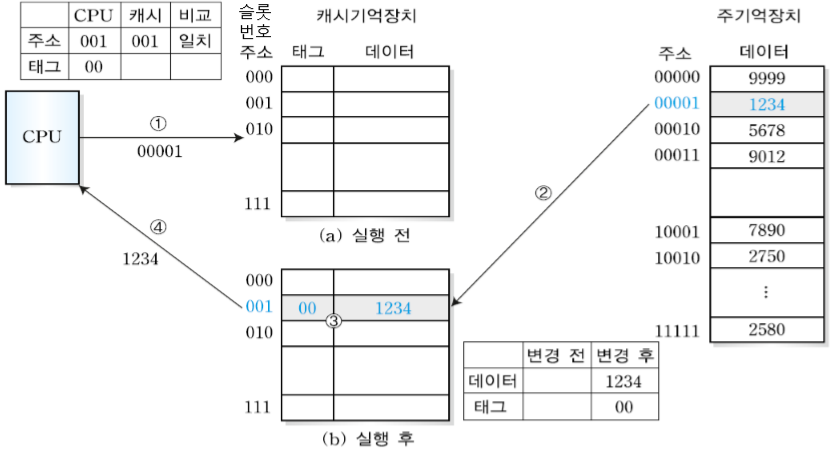
① 캐시 기억장치에 아무 데이터도 없으므로 무조건 miss 상태가 됨
② 주기억장치에서 00001번지를 가져와 앞 두 숫자인 00을 태그에 나머지 숫자 001을 슬롯 번호에 저장하고 데이터인 1234를 저장한다.
③ CPU에 데이터인 1234를 전달한다.
(2) CPU가 00010주소 번지 블록을 필요로 하는 경우
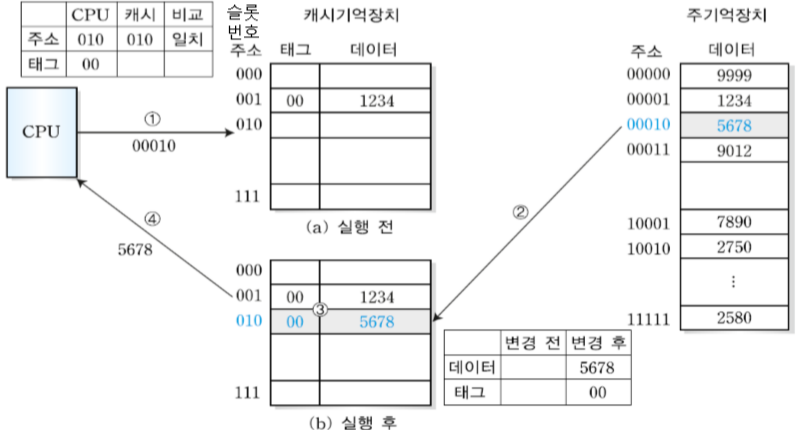
① 캐시 기억장치에서 슬롯 번호(주소)가 010이고 태그가 00인 데이터를 찾을 때 태그가 같은 블록은 있지만 같은 슬롯 번호는 없으므로 개시 기억장치에는 없다고 판단하여 miss 상태가 됨
② 주기억장치에서 00010번지를 가져와 앞 두 숫자인 00을 태그에 나머지 숫자 010을 슬롯 번호에 저장하고 데이터인 5678를 저장한다.
③ CPU에 데이터인 5678을 전달한다.
(3) CPU가 10001주소 번지 블록을 필요로 하는 경우

① 캐시 기억장치에서 슬롯 번호(주소)가 001이고 태그가 10인 데이터를 찾을 때 슬롯 번호가 동일한 데이터를 찾았지만 태그가 다르기 때문에 miss 상태가 됨
② 주기억장치에서 10001번지를 가져와 앞 두 숫자인 10을 태그에 나머지 숫자 001을 슬롯 번호에 저장하고 데이터인 1234를 저장한다. 이때, 캐시 기억장치의 001 번지 태그가 10으로 데이터가 7890으로 바뀌는 것이다. (추가 X)
③ CPU에 데이터인 7890을 전달한다.
(4) CPU가 00010주소 번지 블록을 필요로 하는 경우

① 캐시 기억장치에서 슬롯 번호(주소)가 010이고 태그가 00인 데이터를 찾을 때 슬롯 번호가 동일한 데이터를 찾았을 때 조건에 부합하는 hit로 판단함
② 캐시 기억장치에서 태그가 00이고 슬롯 번호가 010인 데이터 5678을 CPU에 전달한다.
(2) 연관 사상
- 캐시 슬롯번호에 상관없이, 주기억장치의 데이터 블록을 캐시 기억장치의 임의의 위치에 저장하는 것
- 캐시 기억장치로부터 데이터 블록 인출을 위해 모든 슬롯에 대한 검색이 필요하다
- 주소 형식

- 주기억장치에서 가져온 워드를 캐시 기억장치의 임의의 위치에 저장한다

(3) 직접 연관 사상
- 직접 사상과 연관 사상 방식을 조합한 방식이다
- 캐시는 v개의 집합들로 나뉘며, 각 집합들은 k개의 슬롯들로 구성된다
- 직접 사상 방식에 의해, v개의 집합들 중 하나의 집합을 선택한다
- 연관 사상 방식에 의해, 선택한 집합내에 있는 k개의 슬롯 중 하나의 슬롯을 선택한다
- 주소 형식


4) 교체 알고리즘
- 캐시 기억장치의 모든 슬롯이 데이터로 채워져 있는 상태에서 miss일 때, 주기억장치로부터 새로운 데이터 블록을 캐시기억장치로 옮기기 위해 캐시 기억장치의 어느 슬롯 데이터를 제거할지 결정하는 방식이다.
- 캐시가 꽉 찼는데 CPU가 원하는 데이터가 없을 때 어느 데이터부터 없애야 할지에 대한 산택 방식
- 직접 사상 -> 교체 알고리즘이 필요 없다
- 연관 & 집합 연관 사상 -> 교체 알고리즘이 필요하다
- 종류
· LRU (Least Recently Used) : 최소 최근 사용 알고리즘
· LFU (Least Frequently Used) : 최소 사용 빈도 알고리즘
· FIFO (First In First Out) : 선입력 선출력 알고리즘
· RANDOM : 랜덤
5) 쓰기 정책
(1) 즉시 쓰기 방식 (Write-though)
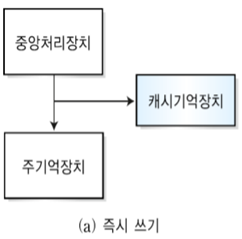
- CPU에서 생성되는 데이터 블록을 캐시 기억장치와 주기억장치에 동시에 기록한다
- 장점 : 데이터의 일관성을 쉽게 보장할 수 있다
- 단점 : 매번 쓰기 동작이 발생할 때마다 캐시 기억장치와 주기억장치 간의 접근이 빈번하게 일어나 쓰기 시간이 길어진다
(2) 나중 쓰기 방식 (Write-back)
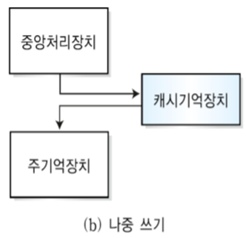
- 명령어를 모아 한번에 기록하는 방식
- 캐시 기억장치에 기록한 후, 기록된 블록에 대한 교체가 일어날 때 주기억장치에 기록함
- 장점 : 즉시 쓰기 방식과는 달리 주기억장치에 기록하는 동작을 최소화할 수 있다
- 단점 : 캐시 기억장치와 주기억장치의 데이터가 서로 일치하지 않을 수 있다
6) 블록 크기
- 블록의 크기가 클수록 한번에 많은 정보를 읽어올 수 있지만 인출 시간이 길어짐
- 블록이 커질수록 캐시기억장치에 적재할 수 있는 블록의 수가 감소해 블록들이 더 빈번하게 교체됨
- 일반적인 적당한 블록의 크기는 4~8word이다
7) 캐시 기억장치의 수
- 시스템 성능 향상을 위해 다수의 캐시가 기억장치들을 사용하는 것이 보편화 되었다
- 캐시 기억장치들을 계층적 구조나 기능적 구조로 설치한다
3. 퀴즈
1) 퀴즈1 - 캐시 기억장치
Q1) 캐시 기억장치의 특징으로 틀린 것을 고르시오. ( )
(1) 자주 사용하는 명령어들을 CPU에 빠르게 전달해 준다
(2) 캐시 기억장치의 용량에 따라 CPU의 가격이 정해진다
(3) 동작이 느린 보조기억장치와 빠른 주기억장치 사이에서 속도 차이를 줄여주는 고속 완충 기억장치의 역할을 한다
(4) 명령어와 데이터를 저장하고 인출하는 속도가 주기억장치보다 빠르다
Q2) CPU가 명령어를 인출하기 위해 캐시 기억장치에 접근했을 때 명령어를 찾으면 ( )이고, 명령어를 찾지 못하면 ( )이다.
Q3) $T_{cache}$가 60ns이고 $T_{main}$ = 550ns 일 때, 적중률은 90%이다. 이 때 $T_{average}$는?
Q4) 직접 사상 방식을 통해 10010번지의 데이터를 불러올 때 캐시 기억장치에 없어 miss인 상황이 되었다. 주기억장치에서 가져온 블록의 슬롯 번호는 ( )이고 태그는 ( )이다.
Q5) 교체 알고리즘이 필요 없는 사상은 ( 직접 사상 / 연관 사상 / 집합 연관 사상 )이다.
Q6) CPU에서 생성되는 데이터 블록을 캐시 기억장치와 주기억장치에 동시에 기록하는 방식은 ( ) 방식이고, 명령어를 캐시장치에 모아두었다 한 번에 기록하는 방식은 ( ) 방식이다.
Q7) 블록의 크기가 작아질수록 한번에 많은 정보를 읽어올 수 있지만 인출 시간은 짧아진다. ( O / X)
< 정답 >
A1) (3)
캐시 기억장치는 보조기억장치와 주기억장치 사이에서 속도 차이를 줄여주는 역할이 아닌 동작이 느린 주기억장치와 빠른 CPU 사이에서 속도 차를 줄여주는 역할을 한다.
A2) (1) hit
(2) miss
A3) 109ns
$T_{average}$ = 적중률 * $T_{cache}$ + (1 – 적중률) * $T_{main}$이므로 0.9 *60 + 0.1 * 550 = 109이다.
A4) (1) 010
(2) 10
A5) 직접 사상
연관 사상과 집합 연관 사상은 교체 알고리즘은 교체 알고리즘이 필요하지만 직접 사상은 필요하지 않다.
A6) (1) 즉시 쓰기 방식
(2) 나중 쓰기 방식
A7) X
위의 설명은 블록의 크기가 작을 때가 아니라 블록이 클수록에 대한 설명이므로 틀렸다.
2) 퀴즈2 - 보조기억장치, 입력과 출력, 시스템 버스
Q1) 보조기억장치의 종류로 옳지 않은 것은?
(1) 플로피 디스크
(2) flash
(3) ROM
(4) 하드 디스크
Q2) 자기 디스크의 설명으로 틀린 것을 고르시오. ( )
(1) 자기 디스크는 양면이 자성재료로 피복되어 있는 원형 평판으로 되어있는 기록장치이다
(2) 자기 디스크의 헤드에서 전도성 코일을 통해 원형 평판의 표면을 자화 시켜 데이터를 저장하거나 검색한다
(3) 자기 디스크의 고정 헤드는 하나의 헤드가 원형평판위를 이동하며 여러 트랙에 읽기와 쓰기를 수행한다
(4) 자기 디스크의 디스크 팔은 헤드를 이동시키는 장치이다
Q3) 설명에 맞는 입출력 명령을 연결시키시오.
| a. 제어 b. 검사 c. 읽기 d. 쓰기 |
(1) 입출력 모듈과 주변장치들의 상태를 검사하는데 사용한다. ( )
(2) 입출력 모듈이 데이터 버스에서 데이터를 받아 주변자치로 보낸다. ( )
(3) 주변 장치를 활성화시키고 무엇을 해야 하는지 알리는 데 사용한다, ( )
(4) 입출력 모듈이 주변장치에서 데이터를 읽고 내부 레지스터에 저장한다. ( )
Q4) 직접 기억장치 액세스(DMA)방식에 대한 설명으로 옳지 않은 것을 고르시오. ( )
(1) DMA 제어기는 전송의 시작과 마지막에만 입출력 동작에 관여한다.
(2) 입출력 버스를 이용한 DMA 방식은 입출력 버스를 활용해 데이터 전송 과정에서 시스템 버스를 한번만 사용한다.
(3) 단일버스 통합형 DMA 방식은 데이터 전송을 위해 시스템 버스를 한번만 사용한다.
(4) 단일버스 분리식 DMA 방식은 데이터 전송을 위해 시스템 버스를 두번씩 사용해야한다.
< 정답 >
A1) (3)
모두 보조기억장치 종류 중 하나지만 ROM은 주기억장치이다.
A2) (3)
(3)에 대한 설명은 자기 디스크의 고정 헤드가 아닌 이동 헤드에 대한 설명이다.
A3) (1) b (2) d (3) a (4) c
| 입출력 명령 | 내용 |
| 제어 (control) | 주변장치를 활성화시키고 무엇을 해야 하는지 알리는 데 사용한다 |
| 검사 (test) | 입출력 모듈과 주변장치들의 상태를 검사는 데 사용된다 |
| 읽기 (read) | 입출력 모듈이 주변장치에서 데이터를 읽고 내부 레지스터에 저장한다 |
| 쓰기 (write) | 입출력 모듈이 데이터 버스에서 데이터를 받아 주변장치로 보낸다 |
A4) (1)
다른 설명은 모두 맞지만 (1)에서 DMA 제어기는 모든 입출력 동작을 전담한다. 전송의 시작과 마지막에만 입출력 동작에 관여하는 것은 CPU이다.
A5) (1) 데이터 버스 (2) 비트들
'Study > 컴퓨터 구조' 카테고리의 다른 글
| 컴퓨터 구조 - MIPS 구조 (0) | 2020.06.12 |
|---|---|
| 컴퓨터 구조 - 분기 명령어와 서브루틴 (0) | 2020.05.29 |
| 컴퓨터 구조 - 메모리 구조와 레지스터 (0) | 2020.05.23 |
| 컴퓨터 구조 - 명령어를 효과적으로 실행하기 위한 기법 (0) | 2020.05.23 |
| 컴퓨터 구조 - 어셈블리 언어 (0) | 2020.04.18 |




댓글